

How ITSM, ITOM & AIOps Are Reshaping IT Operations
Building integrated observability pipelines to enable proactive incident handling and intelligent automation

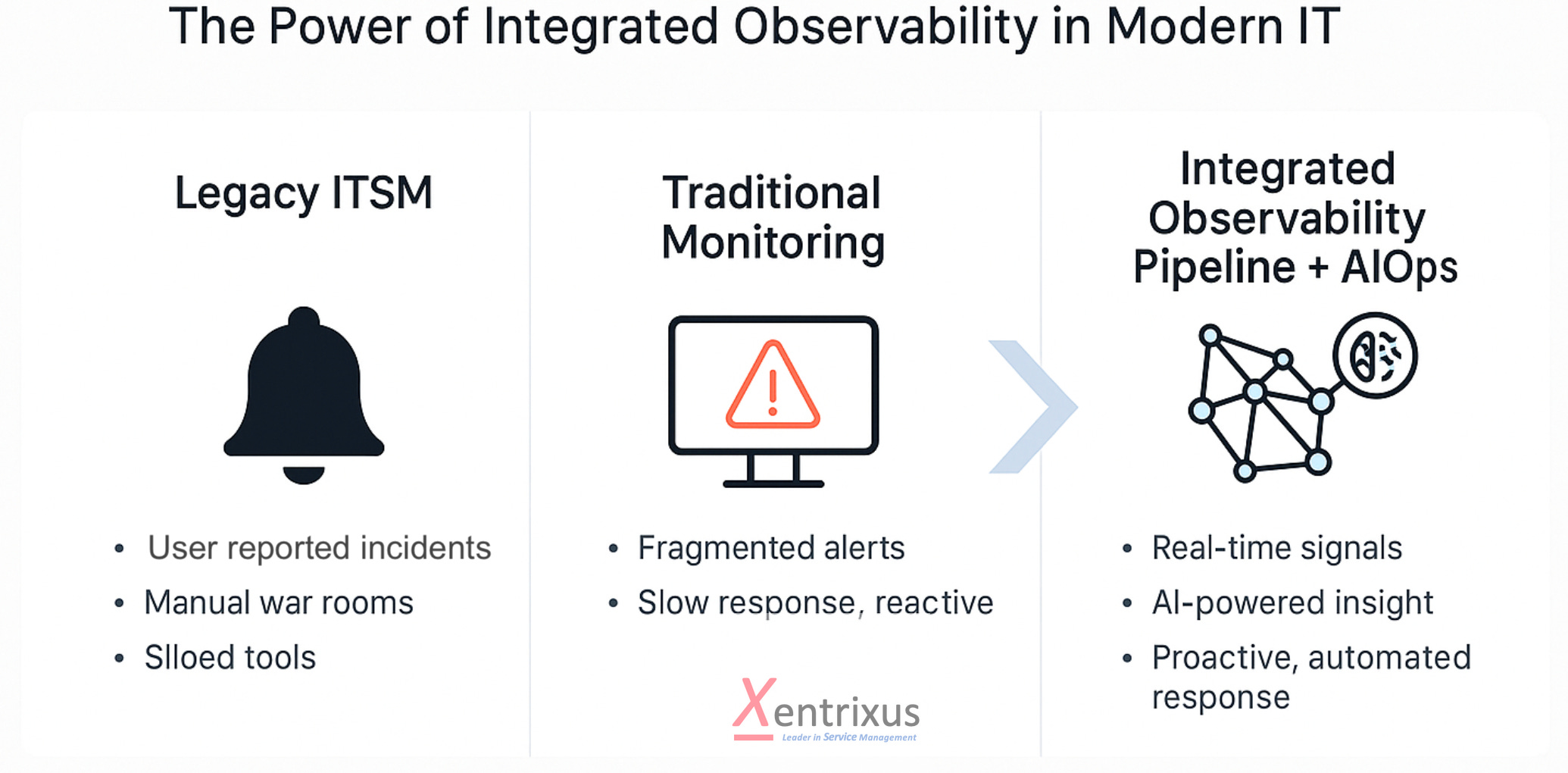
There comes a point in every IT career when you realize you’re not jus…
Keep reading with a 7-day free trial
Subscribe to Xentrixus to keep reading this post and get 7 days of free access to the full post archives.